
 来源|每帧县:视频分割和光流的联合学习
来源|每帧县:视频分割和光流的联合学习
编译|卡罗尔
出品| AI技术大本营(ID: rgznai 100)
唐科技研究团队发表论文《Every Frame Counts: Joint Learning of VideoSegmentation and Optical Flow》,被2020录用。
语义视频分割的主要挑战之一是缺乏标注数据。在大多数基准数据集中,每个视频序列(20帧)只有一帧被标记,这使得大多数监控方法无法利用剩余的数据。为了利用视频中的时空信息,许多现有的工作使用预先计算的光流来提高视频分割的性能,但视频分割和语义分割仍然被视为两个独立的任务。
本文提出了一种新的光流和语义分割的联合学习方案。语义分割为光流和遮挡估计提供了更丰富的语义信息,而非遮挡光流保证了语义分割在像素级的时间一致性。作者提出的语义分割方案不仅可以利用视频中的所有图像帧,而且在测试阶段不会增加额外的计算量。
背景:
通过利用前后帧的语义信息,视频分割往往比图像分割具有更高的准确率,因此在机器人和自动驾驶领域得到了广泛的应用。然而,目前视频语义分割主要面临两个挑战:标注数据的缺乏和实时性问题。
一方面,由于标注耗时耗力,一个视频片段往往只标注一帧,这使得很多方法很难使用所有的数据,或者需要额外的数据集进行预训练;另一方面,由于前后帧之间的信息交互往往会给模型引入额外的模块,导致视频分割效率较低。
视频分割大致可以分为两类。第一类利用前后帧的定时信息加速视频分割,如时钟工作网(Shelhamer等2016)、深度特征流(朱等2017)和(李、石、林2018)等。这种模型只需对前一帧的特征图或分割结果进行简单的处理,就可以得到下一帧的分割结果,从而大大减少了视频分割中的冗余和加速,但语义分割的准确率会降低;
第二类方法,如(Fayyaz等2016),Netwarp (Gadde,Jampani,和Gehler 2017),PEARL(金等2017)等。通过光流/RNN等模块融合前后帧的特征或添加约束,学习更多的表达能力,从而提高语义分割的准确率。本文的方法属于第二类。
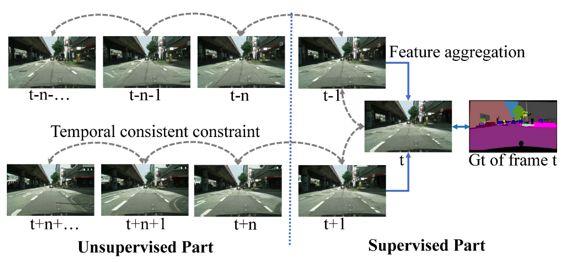 图1相比于特征聚合的方法往往只使用标记帧附近的几帧,本文通过学习到的光流对视频帧增加了一个时序一致性约束,通过这个约束可以将分割后的标记间接传输到其他未标记帧,从而利用所有的数据。
图1相比于特征聚合的方法往往只使用标记帧附近的几帧,本文通过学习到的光流对视频帧增加了一个时序一致性约束,通过这个约束可以将分割后的标记间接传输到其他未标记帧,从而利用所有的数据。
方法概述:
由于视频中前后帧的像素级相关性,光线在视频语义分割中一直扮演着重要的角色。如(李、石、林2018;朱等。2017;Shelhamer等2016)通过光流复用前一帧的特征图,加速视频分割;(Fayyaz等人2016;金等2017;盖德、詹帕尼、盖乐2017;尼尔森和斯敏奇塞斯库2018;Hur和Roth 2016)通过光流引导的特征融合获得更好的分割精度。
然而,上述方法面临两个问题。一方面,他们往往使用现成的在其他数据集上训练的光流网模型,导致分割效率降低;另一方面,上述方法往往只使用了标准帧附近的几帧,而没有充分利用整个数据集,发挥光流的作用。
为了解决以上两个问题,作者提出了光流和语义分割的联合学习框架。语义分割为光流和遮挡估计提供了更丰富的语义信息,而非遮挡光流保证了语义分割像素级的时间一致性。
该模型在视频中无监督地学习光流,并利用光流对前后帧语义分割的特征图施加约束,使两个任务互为增益,不存在显式的特征融合。这种隐式约束可以帮助使用数据集中的所有数据并学习更鲁棒的分割特征来提高分割精度,并且不会增加测试阶段的额外计算。
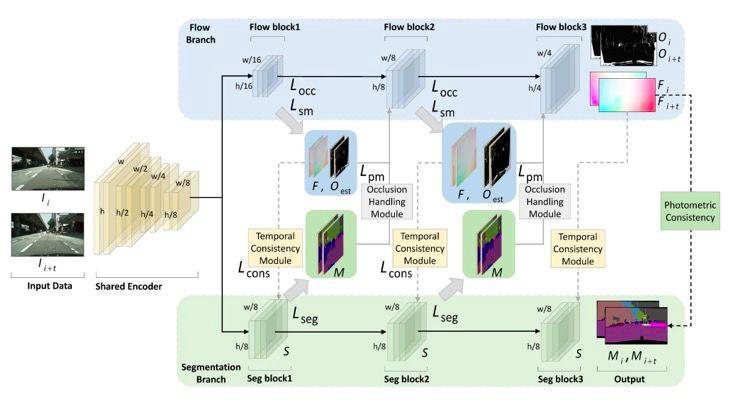 图2,本文提出的联合学习框架,输入图片共享编码器后分为两个分支,第一个是光流分支,第二个是分割分支。方块表示模型的特征图,灰色虚线表示时序一致性约束,灰色实线表示遮挡估计模块。
图2,本文提出的联合学习框架,输入图片共享编码器后分为两个分支,第一个是光流分支,第二个是分割分支。方块表示模型的特征图,灰色虚线表示时序一致性约束,灰色实线表示遮挡估计模块。
时间一致性约束:
对于一对图片I_i和I_{i t},设其对应的分割特征图为S,设学习到的光流为F,遮挡掩膜为O,(S,F,O都包含三个块,如图所示),那么这两帧分割特征图就可以通过光流warp进行转换:S _ I {WARP}=WARP (S _ {I T
考虑到被阻挡的截断区域不能通过光流来对准,因此没有计算这些区域的损耗。光流变形对齐后两帧的其他区域对应的分割特征图的一致性损失为变形后第一帧的分割特征图和第二帧的分割特征图的非遮挡区域的2范数。
光线和遮挡估计:
本文所说的遮挡是指两幅图像之间的光度不一致,一般是由于图像中的遮挡、截断(汽车离开相机进行拍摄)、运动物体等原因造成的。这里作者采用无监督的方式学习遮挡区域,通过反向光流推断出可能没有对齐的像素位置O,模型根据这个学习得到O _ { est };两帧的分割结果由光流扭曲不一致的区域设置为O_{seg}。O_{seg}应该包括遮挡区域和光流估计错误的区域,所以O_{error}=O_{seg}-O_{est}应该是光流估计的关键区域。在计算光流估计的损失函数时,作者没有考虑遮挡区域的损失(O_{est}),而是增加了关键区域的权重(O_{error})。图3示出了遮挡估计的示意图。
图3,遮挡和遮挡估计的示意图
语义分割学习:
在训练过程中,作者从每个视频片段中随机选取10对图片进行训练,其中5对包含带标签的帧,另外5对不包含带标签的帧。对于标记帧,监督语义分割损失直接用于学习;对于不包含标注框架的情况,通过两个框架的一致性约束来约束和学习模型。通过这种约束学习,已标记的信息可以从一帧传播到其他未标记的帧,甚至可以通过一致性学习两个未标记的帧。
实验结果:
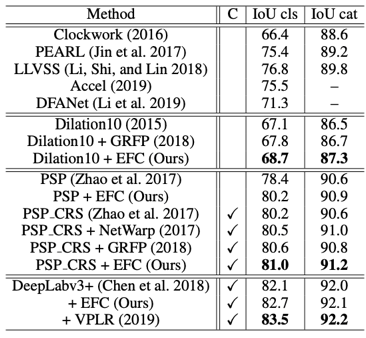
Cityscapes数据集上的分割结果:
CamVid数据集上的分割结果:
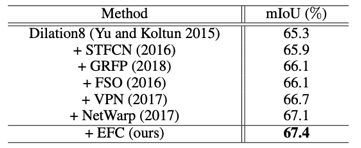
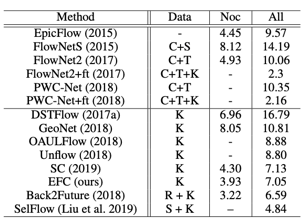
KITTI数据集上的光流估计结果:
可视化结果:
 图4,Cityscapes验证集分割结果,从上到下,原始图像,算法分割结果,PSPNet分割结果和GT。可以看出,本文的算法对运动目标(汽车、自行车)和出现频率较少的目标(横向货车)都有很好的分割效果。
图4,Cityscapes验证集分割结果,从上到下,原始图像,算法分割结果,PSPNet分割结果和GT。可以看出,本文的算法对运动目标(汽车、自行车)和出现频率较少的目标(横向货车)都有很好的分割效果。
图5,KITTI数据集上的光流估计结果。从上到下分别展示了原图、本文算法估算结果、GeoNet估算结果和GT。可以看出,该算法对于运动目标的边缘估计更加准确。
论文:每帧:联合学习视频分割和光流
作者:明宇鼎,周,简,支五路,平罗
地址:https://arxiv.org/pdf/1911.12739.pdf
